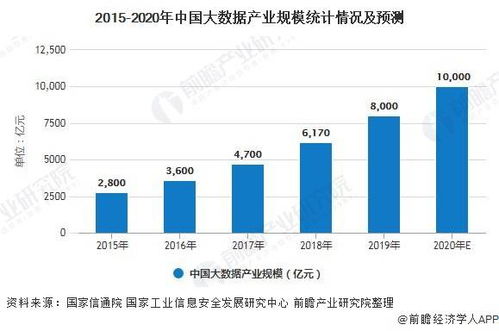
大數(shù)據(jù)架構(gòu)與模式(五) 基于解決方案模式與產(chǎn)品選型的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)
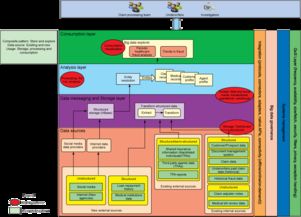
在構(gòu)建大數(shù)據(jù)系統(tǒng)時(shí),將通用解決方案模式與具體的產(chǎn)品技術(shù)相結(jié)合,是確保系統(tǒng)高效、可靠且可擴(kuò)展的關(guān)鍵。本部分聚焦于如何針對(duì)特定的大數(shù)據(jù)問題應(yīng)用已驗(yàn)證的解決方案模式,并在此基礎(chǔ)上選擇合適的技術(shù)產(chǎn)品,以構(gòu)建強(qiáng)大的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)體系。
一、 核心大數(shù)據(jù)解決方案模式的應(yīng)用
面對(duì)海量、多源、高速的數(shù)據(jù),典型的解決方案模式為技術(shù)選型提供了藍(lán)圖。
- 數(shù)據(jù)采集與注入模式:針對(duì)不同數(shù)據(jù)源(日志、傳感器、數(shù)據(jù)庫變更、消息隊(duì)列等),采用相應(yīng)的模式。例如,對(duì)于實(shí)時(shí)流數(shù)據(jù),應(yīng)用“發(fā)布-訂閱”或“事件流處理”模式;對(duì)于批量歷史數(shù)據(jù),則采用“批量提取與加載”模式。模式的選擇直接決定了后續(xù)對(duì)采集工具(如Flume, Kafka, Sqoop, Debezium)的需求。
- 數(shù)據(jù)存儲(chǔ)與組織模式:根據(jù)數(shù)據(jù)的結(jié)構(gòu)、訪問模式和一致性要求,混合使用多種存儲(chǔ)模式。這包括:
- 原始數(shù)據(jù)湖模式:用于存儲(chǔ)未經(jīng)處理的原始數(shù)據(jù),支持任意格式,為探索性分析保留靈活性。
- 分層存儲(chǔ)與“Lambda/Kappa架構(gòu)”模式:結(jié)合批處理和流處理路徑,構(gòu)建熱、溫、冷數(shù)據(jù)分層,平衡成本與性能。
- 多模型存儲(chǔ)模式:根據(jù)具體場(chǎng)景,組合使用鍵值存儲(chǔ)、文檔數(shù)據(jù)庫、列式存儲(chǔ)、圖數(shù)據(jù)庫等,而非依賴單一存儲(chǔ)解決所有問題。
- 數(shù)據(jù)處理與分析模式:
- 批處理模式:適用于對(duì)數(shù)據(jù)完整性、準(zhǔn)確性要求高,但時(shí)效性要求相對(duì)寬松的場(chǎng)景,如日終報(bào)表、歷史數(shù)據(jù)挖掘。
- 流處理模式:適用于需要實(shí)時(shí)響應(yīng)的場(chǎng)景,如欺詐檢測(cè)、實(shí)時(shí)監(jiān)控。微批處理和連續(xù)處理是其主要實(shí)現(xiàn)方式。
- 交互式查詢模式:服務(wù)于數(shù)據(jù)探索和即席查詢,要求低延遲的SQL或類SQL接口。
- 機(jī)器學(xué)習(xí)管道模式:標(biāo)準(zhǔn)化數(shù)據(jù)清洗、特征工程、模型訓(xùn)練與評(píng)估、模型部署的流程。
二、 基于模式的產(chǎn)品選型策略
在明確解決方案模式后,產(chǎn)品選型需綜合考慮多個(gè)維度,避免技術(shù)堆砌。
- 匹配模式與產(chǎn)品能力:將模式需求映射到產(chǎn)品特性。例如:
- 流處理模式 → 評(píng)估Apache Flink(狀態(tài)化精確一次處理)、Apache Spark Streaming(微批處理)、Apache Kafka Streams(輕量級(jí)庫)在吞吐量、延遲、狀態(tài)管理、容錯(cuò)方面的差異。
- 交互式查詢模式 → 對(duì)比Apache Hive on Tez/LLAP、Presto/Trino、ClickHouse、Impala等在ANSI SQL支持、多數(shù)據(jù)源聯(lián)邦查詢、并發(fā)能力和響應(yīng)速度上的表現(xiàn)。
- 生態(tài)系統(tǒng)與集成度:優(yōu)先選擇與現(xiàn)有或計(jì)劃中的技術(shù)棧集成良好的產(chǎn)品。例如,在Hadoop生態(tài)內(nèi),Spark、Hive、HDFS的集成更為順暢;在云原生環(huán)境下,Kubernetes與Flink、Presto的云托管服務(wù)(如AWS EMR, Azure HDInsight, GCP Dataproc)可能是更優(yōu)選擇。
- 可擴(kuò)展性與運(yùn)維成本:評(píng)估產(chǎn)品的水平擴(kuò)展能力、監(jiān)控管理工具的成熟度以及社區(qū)/商業(yè)支持的力度。開源產(chǎn)品活躍的社區(qū)是重要資產(chǎn),而商業(yè)發(fā)行版或云托管服務(wù)則能降低運(yùn)維復(fù)雜性。
- 總擁有成本(TCO):除了軟件許可費(fèi)用(如有),更需計(jì)算硬件資源消耗、人力運(yùn)維成本以及云環(huán)境下的具體計(jì)費(fèi)模型(存儲(chǔ)、計(jì)算、數(shù)據(jù)傳輸)。
三、 構(gòu)建數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)
最終目標(biāo)是將選定的產(chǎn)品組合,以服務(wù)的形式提供穩(wěn)定、高效的數(shù)據(jù)支撐能力。
- 統(tǒng)一的數(shù)據(jù)接入服務(wù):基于采集模式,構(gòu)建標(biāo)準(zhǔn)化的API、SDK或配置化工具,屏蔽底層Kafka、Flume等產(chǎn)品的復(fù)雜性,為業(yè)務(wù)方提供簡便的數(shù)據(jù)注入通道。
- 彈性的數(shù)據(jù)存儲(chǔ)服務(wù):整合對(duì)象存儲(chǔ)(如AWS S3)、分布式文件系統(tǒng)(HDFS)、各類NoSQL數(shù)據(jù)庫及數(shù)據(jù)倉庫,通過統(tǒng)一的元數(shù)據(jù)管理層(如Apache Hive Metastore, AWS Glue Data Catalog)提供一致的數(shù)據(jù)目錄和訪問視圖。實(shí)施智能的生命周期管理策略,自動(dòng)將數(shù)據(jù)在不同存儲(chǔ)層間遷移。
- 多樣化的數(shù)據(jù)處理服務(wù):提供菜單式的處理能力:
- 批量計(jì)算服務(wù):基于Spark或MapReduce引擎,提供任務(wù)調(diào)度(Airflow, DolphinScheduler)、資源隊(duì)列管理。
- 流計(jì)算服務(wù):提供Flink或Spark Streaming作業(yè)的托管平臺(tái),支持作業(yè)提交、狀態(tài)監(jiān)控、彈性擴(kuò)縮容。
- 即席查詢服務(wù):部署Presto/Trino集群,并提供查詢網(wǎng)關(guān)、多租戶資源隔離和查詢歷史分析。
- 數(shù)據(jù)治理與質(zhì)量服務(wù):這是支持服務(wù)的“軟實(shí)力”核心。集成數(shù)據(jù)血緣追蹤、數(shù)據(jù)質(zhì)量校驗(yàn)規(guī)則引擎、敏感數(shù)據(jù)脫敏與安全策略,確保在高效處理的保障數(shù)據(jù)的可靠性、安全性與合規(guī)性。
- 平臺(tái)化與自助服務(wù):通過平臺(tái)門戶將上述服務(wù)能力產(chǎn)品化。數(shù)據(jù)開發(fā)者可以自助申請(qǐng)資源、提交作業(yè)、管理管道;數(shù)據(jù)分析師可以自助探索數(shù)據(jù)、運(yùn)行查詢、獲取數(shù)據(jù)集。
###
成功的大數(shù)據(jù)架構(gòu)并非最新技術(shù)的簡單羅列,而是針對(duì)業(yè)務(wù)問題,精準(zhǔn)應(yīng)用解決方案模式,并理性選擇與之匹配的技術(shù)產(chǎn)品的結(jié)果。最終形成的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù),應(yīng)是一個(gè)平臺(tái)化、自動(dòng)化、智能化的支撐體系,它能夠靈活適配多變的業(yè)務(wù)需求,同時(shí)確保數(shù)據(jù)資產(chǎn)被安全、高效、可持續(xù)地管理和利用,從而為數(shù)據(jù)驅(qū)動(dòng)決策奠定堅(jiān)實(shí)的技術(shù)基礎(chǔ)。從模式到產(chǎn)品,再到服務(wù),是實(shí)現(xiàn)大數(shù)據(jù)價(jià)值最大化的系統(tǒng)化路徑。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.cmj.org.cn/product/51.html
更新時(shí)間:2026-02-24 21:46:58