Java大視界 大數據在智慧港口集裝箱調度與物流效率提升中的應用創新
在當今全球貿易與供應鏈日益復雜的背景下,港口作為物流樞紐的核心節點,其運營效率直接影響著整個經濟體系的流暢度。傳統港口作業模式,特別是集裝箱調度與物流管理,常面臨信息孤島、響應滯后、資源錯配等挑戰。而Java技術與大數據生態的深度融合,正為智慧港口的轉型升級提供了強大引擎。本文將聚焦于Java大數據技術棧,探討其在智慧港口集裝箱調度與物流效率提升中的關鍵應用與創新實踐,特別是其作為數據處理和存儲核心支持服務的角色。
一、 智慧港口的核心挑戰與大數據機遇
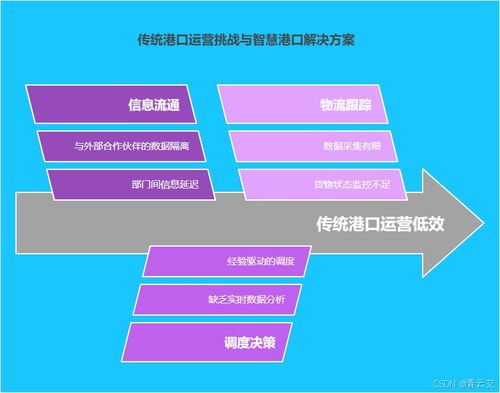
港口集裝箱調度是一個涉及船舶、岸橋、場橋、集卡、堆場、閘口等多要素的復雜動態系統。效率瓶頸往往源于:
- 信息碎片化:來自船舶AIS、碼頭操作系統(TOS)、設備傳感器、海關報關等系統的數據格式不一,實時整合難。
- 預測能力弱:靠泊計劃、堆場策劃、陸運提箱等環節依賴經驗,難以精準預測擁堵和需求波動。
- 實時響應不足:面對天氣變化、船舶延誤等突發事件,傳統系統調整緩慢,易引發連鎖延誤。
大數據技術,尤其是構建在Java生態系統(如Hadoop、Spark、Flink、Kafka)之上的解決方案,能夠匯聚、處理海量多源異構數據,并通過實時計算與智能算法,將數據轉化為可行動的洞察,從而應對上述挑戰。
二、 Java大數據技術棧:數據處理與存儲的核心支柱
Java以其穩定性、跨平臺性及豐富的開源生態,成為構建企業級大數據平臺的基石。在智慧港口場景中,其關鍵支撐作用體現在:
1. 海量數據采集與實時接入
- Apache Kafka(基于Scala/Java):作為高吞吐量的分布式消息隊列,充當港口數據“中樞神經”。它能實時接入船舶AIS信號、集裝箱RFID/GPS數據、岸橋傳感器讀數、閘口識別影像流等,實現毫秒級的數據管道,為后續實時分析奠定基礎。
2. 批流一體的數據處理引擎
- Apache Spark(核心API為Scala/Java):其內存計算框架非常適合港口歷史作業數據的批量分析(如月度吞吐量統計、航線效率分析)與復雜的機器學習模型訓練。
- Apache Flink(Java/Scala API):真正的流處理優先引擎,適用于對實時性要求極高的場景,如基于實時船舶位置的動態靠泊仿真、集卡路徑的秒級重規劃,實現“事件驅動”的調度。
3. 彈性可擴展的數據存儲
- Hadoop HDFS / Apache HBase:提供低成本、高可靠的海量歷史數據存儲,用于存放長期的作業日志、集裝箱軌跡、船舶檔案等,支撐長期趨勢分析和數據挖掘。
- 各類NoSQL及NewSQL數據庫(如Elasticsearch用于日志檢索,Cassandra用于時空數據):滿足不同業務場景下的高性能讀寫與靈活查詢需求。
4. 微服務架構與集成
- 基于Spring Boot/Cloud等Java框架構建的微服務,將大數據分析能力(如預測模型、優化算法)封裝成獨立的、可彈性伸縮的服務。這些服務可以靈活集成到現有的港口TOS、設備控制系統中,實現“數據智能”與“業務操作”的無縫閉環。
三、 應用創新:從數據到智能決策
依托上述Java大數據技術棧的支持,智慧港口的創新應用得以實現:
1. 智能預測與協同調度
- 到港船舶ETA精準預測與泊位預分配:融合AIS歷史數據、天氣海況、港口繁忙度等多維數據,利用Spark MLlib訓練預測模型,提前數小時甚至數天精準預測船舶到港時間,并仿真推演最優泊位分配方案,減少船舶錨地等待。
- 堆場智能策劃與翻箱率優化:通過分析集裝箱的尺寸、重量、目的地、船期等信息,利用優化算法(如遺傳算法)自動生成堆存計劃,最小化后續作業中的翻箱倒柜次數,提升場橋作業效率。
2. 實時動態路徑優化與資源調配
- 集卡無人駕駛/有人駕駛的實時調度:Flink實時處理集裝箱提送箱任務指令、集卡實時位置、道路擁堵信息,動態計算最優派單和行駛路徑,實現集卡“秒級”任務分配與路徑更新,減少空駛和等待。
- 岸橋與場橋的協同作業優化:通過實時分析船舶貝位圖、集裝箱在堆場的位置,動態調整岸橋作業順序和場橋的取箱任務,縮短船舶在港時間。
3. 全程可視化與異常預警
- 物流鏈全程可視化追蹤:基于大數據平臺構建統一的集裝箱數字孿生,從訂艙、進港、裝卸、在途到目的地,全鏈條狀態實時可視。
- 設備預防性維護與異常預警:實時分析岸橋、場橋等關鍵設備的傳感器數據(振動、溫度、電流),利用機器學習模型預測潛在故障,提前安排維護,避免非計劃停機。
四、 挑戰與展望
盡管前景廣闊,智慧港口的大數據應用仍面臨數據質量治理、跨系統集成復雜度高、復合型人才短缺等挑戰。隨著Java生態的持續演進(如Spark/Flink性能優化、云原生部署),以及與5G、物聯網、數字孿生、區塊鏈技術的進一步融合,基于Java大數據的智慧港口系統將向著更實時、更自治、更協同的方向發展,最終實現港口物流資源的全局最優配置與供應鏈的極致韌性。
****
Java大數據技術,作為強大的數據處理與存儲支持服務,正深度重塑智慧港口的運營模式。它不僅是技術工具,更是驅動集裝箱調度從“經驗驅動”邁向“數據智能驅動”的核心變革力量。通過構建統一、實時、智能的數據處理平臺,港口能夠以前所未有的精度和敏捷性應對復雜挑戰,顯著提升物流效率與綜合競爭力,在全球貿易網絡中扮演更智慧、更關鍵的角色。
如若轉載,請注明出處:http://www.cmj.org.cn/product/57.html
更新時間:2026-02-24 01:31:19